

{kind=link}
This article will introduce XML in short by comparing it with HTML, and article will focus on the topic Parsing an XML document in java.
Introduction:
XML stands for eXtensible Markup Language. As it’s name suggest, it allows user to define their own customized markup language. XML is a self descriptive standard of text based file designed to store and transport data. Here in the example we will use XML to store data.
If you are not knowing anything about XML, don’t worry I’m gonna write about it in very common words. It is similar to HTML in the sense that it contains tags like HTML and the file is called XML document. XML document contains values between tags and may contain tags enclosing other tags. XML documents have file extension .xml.
Let’s do a small comparison of HTML and XML.
XML vs HTML
- XML is case sensitive but html is not case sensitive.
- Unlike HTML, You can not omit the closing tags.
- For every attribute must have a value and that value must be enclosed with double quote(“”).
- XML is intended to carry data but HTML focuses on the presentation of data.
Parsing an XML Document:
You will see a basic example of XML document in example bellow. Activity of reading an XML file is parsing. Java library provide two kinds of XML parser.
- The tree Parser like Document Object Model (DOM) parsers.
- Streaming Parser like Simple API for XML (SAX).
Steps In Parsing an XML Document in Java:
Ultimate goal here is to get document object associated with a XML file.
- Get the DocumentBuilderFactory Object- DocumentBuilderFactory is an abstaract class in
Javax.xml.parserspackage. It find the implementation class according to a properties file in jre library and throws FactoryConfigurationError when it do not find implementation class.DocumentBuilderFactory factory=DocumentBuilderFactory.newInstance(); - Get the DocumenBuilder Object- DocumentBuilder abstarct class is also in the same package and it is API to generate an DOM instances for an XML document.
DocumentBuilder builder=factory.newDocumentBuilder(); - Read file and create Document, For this you would need the path of XML file
String path="C://.......//demo.xml"; Document document= builder.parse(new File(path));Document is an interface extending Node interface. It represent the entire XML or HTML document. Document is point where we start exploring the XML document. - Now you start analyzing the Contents of the document. Document interface conatins methods to create, access, rename, adopt and analyze the nodes inside documents.
Exmaple:
Example below will make a clear idea on the above procedure. have a look at source code.
I have created a folder in project directory and then created XML file inside that directory. First have a look at XML file.
xmls\\myinfo.xml
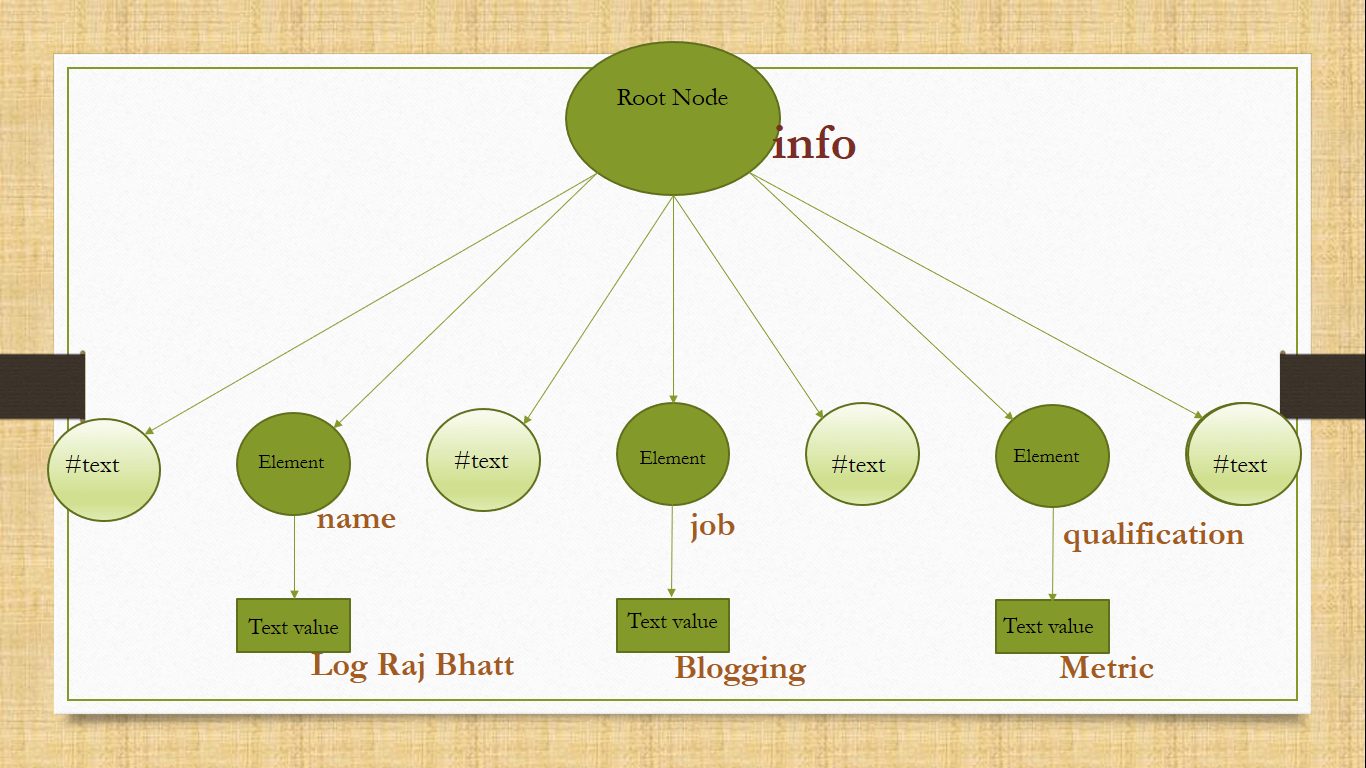
<?xml version="1.0" encoding="UTF-8"?> <info> <name> Log Raj Bhatt </name> <job> Blogger </job> <qualification> Metric </qualification> </info>
This is very much simple XML file without following any DTD standard for validation.
Code to Parse the XML document is in following main class.
XmlMain.java
package xml.main;
import java.io.File;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import org.w3c.dom.*;
public class XmlMain {
public static void main(String[] args)throws Exception {
DocumentBuilderFactory factory=DocumentBuilderFactory.newInstance();
DocumentBuilder db=factory.newDocumentBuilder();
File f=new File("xmls\\myinfo.xml");
Document doc=db.parse(f);
Element root=doc.getDocumentElement();
for(Node node=root.getFirstChild();node!=null;node=node.getNextSibling()) {
if(node instanceof Element) {
String name=node.getNodeName();
String value=node.getTextContent().trim();
System.out.println(name +" --> "+value);
}
}
}
}
In this example i have used a simple XML file containing only three elements inside root element and these also do not contain any attributes. Here child nodes of the root may of the type #text. So I first checked the node whether it is Element or not. Finally The trim() method remove the newline and white space surrounding the text content of elements.
Output:
Output of above program is like this:
name –> Log Raj Bhatt
job –> Blogger
qualification –> Metric
We have more methods to get all child elements at a time and methods to access attributes also. I am gong to insert small diagram explaining above DOM hierarchy for above XML document.

I will later explain about validation of xml using DTD in next posts.